SPM Bench: Benchmarking Affordable LLMs for Malaysian Education (Draft)
How I built SPM Bench to evaluate affordable, vision-aware models for SPM Chat, and why a purpose-built retrieval harness still matters even when base models are already strong.
SPM Chat started as a practical question: can an affordable AI system be reliable enough to help Malaysian students revise for SPM?
As the project grew, I realized I needed something more rigorous than anecdotal wins and isolated demos. That led to SPM Bench, a benchmark built to measure how well low-cost language models answer SPM multiple-choice questions, and how much a purpose-built retrieval harness actually helps.
This write-up summarizes what I learned from the latest benchmark run on this branch, and why the results changed how I think about RAG for education.
Purpose of SPM Bench
The goal of SPM Bench is straightforward: compare affordable models that are realistic for the Malaysian education landscape.
That constraint matters. A benchmark is much less useful if it only tells me which expensive model wins in a lab setting. SPM Chat has to operate under real product constraints:
- Inference cost has to stay low enough for student-facing usage.
- Vision matters because a meaningful share of student questions involve diagrams, graphs, tables, or visual options.
- The system has to work without web search.
- The evaluation should focus on answer quality, not long hidden reasoning traces.
So instead of optimizing for the absolute strongest frontier model regardless of cost, SPM Bench is designed to answer a more practical question:
Given the models that are cheap enough to deploy, which setup is actually best for SPM-style learning tasks?
Dataset Curation
The current benchmark uses 525 clean MCQ questions across 15 papers and 8 subjects, spanning 2024 and 2025 trial papers.
The subjects covered are:
- Fizik
- Kimia
- Biologi
- Matematik
- Sains
- Sejarah
- Ekonomi
- Perniagaan
I deliberately kept the dataset broad across STEM, humanities, and business subjects because a student-facing study assistant does not get to specialize in only one style of question.
Why MCQ Only?
SPM Bench currently evaluates multiple-choice questions only.
The reason is practical: MCQs are easy to verify at scale. Every question has a fixed answer key, so scoring is objective and cheap.
Structured questions are much harder. It is possible to use an LLM as a judge, but that introduces a new layer of cost and uncertainty. Once the evaluator itself becomes a model, benchmark quality depends on how trustworthy the judge is. For an early benchmark, I wanted the scoring to be as simple and stable as possible.
That makes MCQ a good starting point, even though it is not the full picture of SPM performance.
Model Selection Criteria
The models in SPM Bench were chosen using a product-oriented filter rather than a leaderboard-oriented one.
The main criteria were:
- Cheap enough to deploy at scale
- Vision-capable where possible
- No web search
- No requirement for exposed chain-of-thought
This led to a benchmark set centered around low-cost models from major labs, including Gemini Flash Lite variants and OpenAI nano-tier models, with additional baselines used where useful for comparison.
The vision requirement is especially important. Based on SPM Chat usage, a substantial portion of student queries are visual in nature. If a model is cheap but weak on diagrams, charts, and image-based questions, it is much less useful in practice.
For the tables below, I focus on the practical shortlist I cared about most:
- SPM Chat
- Gemini 3.1 Flash Lite
- Gemini 2.5 Flash Lite
- Qwen 3.5 Flash
- GPT-5 Nano
- DeepSeek Chat
Why SPM Chat Needed a Purpose-Built Harness
One of the clearest lessons from this benchmark is that generic retrieval is not enough for this use case.
SPM questions are extremely sensitive to precision. A chunk that is topically related but not exact can still push the model toward the wrong answer. That means retrieval quality is not just about recall. It is about bringing in the right syllabus evidence with minimal noise.
For SPM Chat, I built the evaluation harness around that assumption. The system is designed specifically for syllabus-grounded exam answering rather than generic document search.
This matters because generic vector or embedding-heavy retrieval looked noisy in practice. In the benchmark, Google's generic File Search setup reached 74.1%, which is respectable, but still well behind the purpose-built SPM Chat line. That result matches what I saw in internal experiments: broad semantic retrieval often finds nearby content, but nearby content is not always enough for brittle MCQ tasks.
In other words, a general-purpose RAG stack can look reasonable from a software architecture perspective while still leaving accuracy on the table for a narrow domain like SPM.
Results
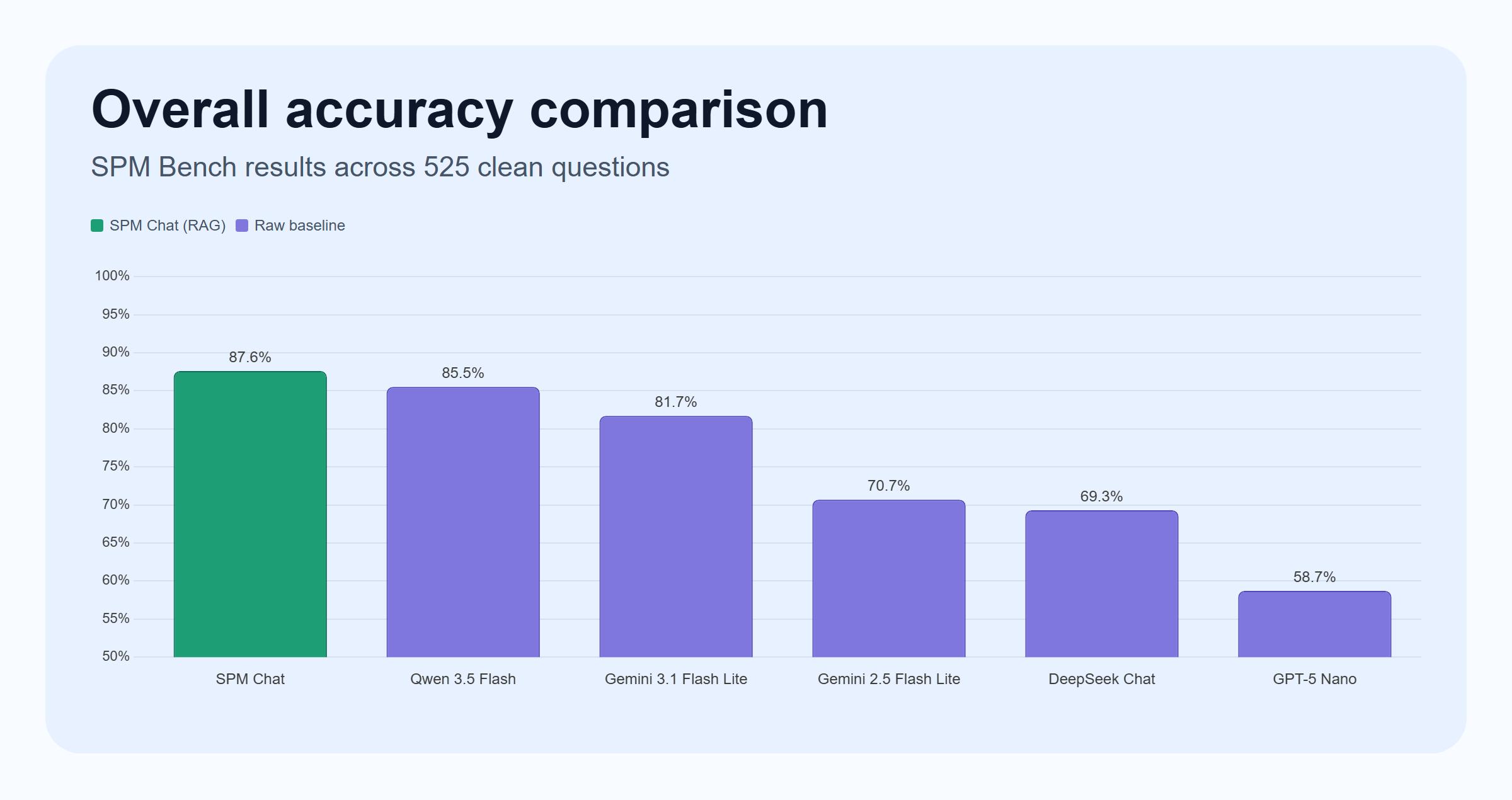
Across the current benchmark, SPM Chat scores 87.6% overall on the 525 clean questions.
That is the number I care about most for the system today. It is high enough to show that a syllabus-aware harness adds real value, but also low enough to be humbling. Before running this benchmark, I would honestly have guessed that SPM Chat was closer to 95%.
The benchmark says otherwise.
Overall Comparison
| Model | Accuracy | Correct / Total | Mean latency | Input / 1M tok | Output / 1M tok |
|---|---|---|---|---|---|
| SPM Chat | 87.6% | 460 / 525 | 16.86 s | - | - |
| Qwen 3.5 Flash | 85.5% | 449 / 525 | 17.52 s | $0.10 | $0.40 |
| Gemini 3.1 Flash Lite | 81.7% | 429 / 525 | 7.26 s | $0.25 | $1.50 |
| Gemini 2.5 Flash Lite | 70.7% | 371 / 525 | 1.36 s | $0.10 | $0.40 |
| DeepSeek Chat | 69.3% | 364 / 525 | 1.55 s | $0.28 | $0.42 |
| GPT-5 Nano | 58.7% | 308 / 525 | 5.43 s | $0.20 | $1.25 |
The first thing that jumps out is that Qwen 3.5 Flash is a very strong raw baseline. It gets surprisingly close to SPM Chat on overall accuracy and outperforms some of the other raw baselines by a wide margin.
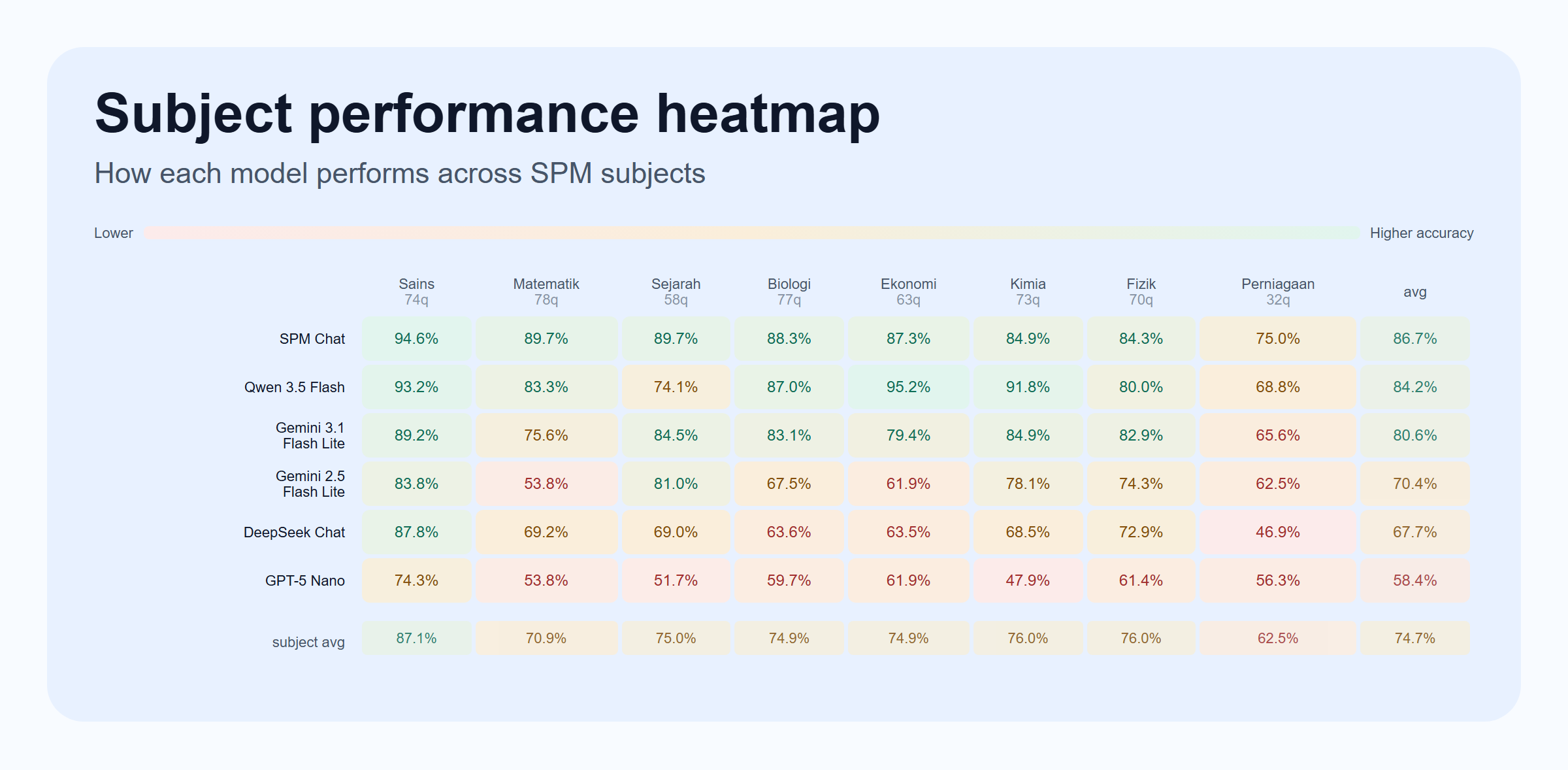
Subject-by-Subject Results
| Subject | Questions | SPM Chat | Gemini 3.1 Flash Lite | Gemini 2.5 Flash Lite | Qwen 3.5 Flash | GPT-5 Nano | DeepSeek Chat |
|---|---|---|---|---|---|---|---|
| Fizik | 70 | 84.3% | 82.9% | 74.3% | 80.0% | 61.4% | 72.9% |
| Kimia | 73 | 84.9% | 84.9% | 78.1% | 91.8% | 47.9% | 68.5% |
| Biologi | 77 | 88.3% | 83.1% | 67.5% | 87.0% | 59.7% | 63.6% |
| Matematik | 78 | 89.7% | 75.6% | 53.8% | 83.3% | 53.8% | 69.2% |
| Sains | 74 | 94.6% | 89.2% | 83.8% | 93.2% | 74.3% | 87.8% |
| Sejarah | 58 | 89.7% | 84.5% | 81.0% | 74.1% | 51.7% | 69.0% |
| Ekonomi | 63 | 87.3% | 79.4% | 61.9% | 95.2% | 61.9% | 63.5% |
| Perniagaan | 32 | 75.0% | 65.6% | 62.5% | 68.8% | 56.3% | 46.9% |
What Stands Out
The first surprise is that the raw base models are already stronger than I expected. A raw Gemini 3.1 Flash Lite baseline reaches 81.7%, and Qwen 3.5 Flash reaches 85.5%, without the full SPM Chat harness.
That is impressive, but it also makes the benchmark more interesting. If the base model is already strong, the job of the retrieval system changes. It is no longer enough to dump in more context and hope for the best. The harness has to add the exact missing evidence without distracting the model.
The second surprise is that Sejarah benefits disproportionately from keyword-style retrieval. Internal experiments showed that keyword-focused search worked especially well for Sejarah compared with broader chapter-style retrieval. That makes intuitive sense: history questions often hinge on named events, committees, policies, or institutions, where literal term matching is a strong signal.
The third lesson is about latency as a retrieval design problem. A better harness is not only about higher accuracy. It is also about keeping the amount of context small and targeted enough that response time stays acceptable. Generic retrieval can be both slower and noisier. For a student product, that is a bad combination.
The fourth lesson is that subject behavior is uneven:
- Sains is already very strong at 94.6%.
- Matematik and Sejarah are close behind at 89.7%.
- Perniagaan is still the weakest subject at 75.0%.
- Qwen 3.5 Flash is particularly strong on Kimia and Ekonomi, which makes it a useful reminder that raw model capability is still moving quickly.
- DeepSeek Chat is a useful speed-cost baseline, but it trails the strongest raw vision-capable models on most subjects in this benchmark.
Why the Results Matter
The benchmark makes a simple point very clearly:
A good use-case-specific harness still matters, even when cheap base models are already strong.
That is the main advantage SPM Chat currently has. The value is not just in picking a capable model. The value is in shaping retrieval and answering around the structure of the syllabus and the behavior of exam questions.
At the same time, the benchmark also challenged my own expectations. I went into this assuming SPM Chat would land closer to 95% accuracy. It did not. Even with a fairly optimized setup, the benchmark shows there is still meaningful room for improvement before I can call the system truly reliable.
What SPM Bench Does Not Capture Well
One important limitation is that SPM Bench mostly measures question answering, not the full value of a syllabus-grounded study assistant.
A model can answer many exam questions correctly and still perform poorly when a student asks:
- what chapters are in a subject
- how a topic fits into the syllabus
- what to revise for a specific form or chapter
- how to generate study notes grounded in the official structure
This matters because usage data shows that about 30% of SPM Chat queries are related to revision or study notes based on syllabus content.
That is a different task from MCQ answering. Even strong base models often do not have a complete mental model of the syllabus structure and can hallucinate when asked for chapter-level or subtopic-level guidance. So while raw LLM performance on MCQs is stronger than many people expect, syllabus-grounded context is still essential for the broader product.
Future Work
SPM Bench is already useful, but it is still early. The obvious next steps are:
- Increase the number of question sets to reduce test variance
- Include more models as the low-cost model landscape evolves
- Experiment with new retrieval and search mechanisms
- Expand the benchmark to structured questions
- Test custom fine-tuned models
The core problem remains the same: not just getting a model to answer more questions correctly, but making the whole system reliable enough to be trusted in a real study workflow.
Closing Thoughts
SPM Bench started as a benchmark, but it ended up being a reality check.
It confirmed that affordable models have become much better than I expected. It also confirmed that a purpose-built syllabus harness still creates real value. But most importantly, it showed that SPM Chat is not "done". The system is already useful, but there is still a gap between a strong demo and a truly dependable study tool.
For me, that is the most valuable outcome of the project so far. A benchmark should not just produce a headline number. It should reveal where the system is actually strong, where it is still fragile, and what kind of engineering work is worth doing next.